Natural Language Proccessing文章解析/自然言語処理
AIサービス:
SyncLect NLP
自然言語処理(文章解析)とは
形態素解析
日本語は、ひらがな、カタカナ、漢字が入り混じる構造になっており、
文字列を単語単位(形態素)に一旦分解する作業を行う必要があります。
これを形態素解析と言います。
形態素解析は、言語解析を行う上で基本とされており、
形態素の組み合わせ次第で、文章が形成されています。
パソコンなどで使われる「かな漢字変換」でも形態素解析技術が使われています。
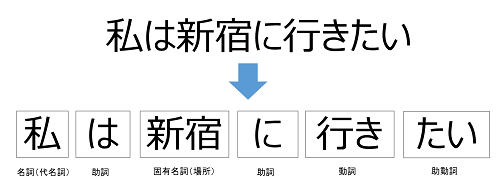
構文解析
構文解析は、文を構成する全ての単語の位置関係を判断しています。
構文とは、「文章の基本形・ルール」のようなものです。
一見馴染みが無いですが、英語の授業で「主語、動詞、目的語」のように文型を覚えた事があると思います。
この構文の形を解析する事で、「文章として成立しているか」を機械に判別させています。
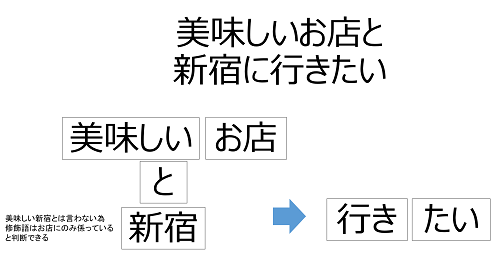
ちなみに「美味しいお店と新宿に行きたい」を例にとると、「美味しい」という修飾語は、「お店」と「新宿」に係っているので、
構文上では、文法自体は成立しています。
なお、構文解析は統語解析、係り受け解析等とも呼ばれています。
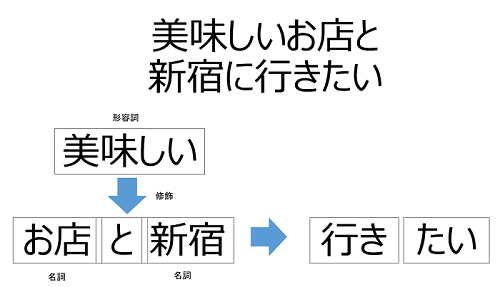
意味解析
「美味しいお店」とは言うが、「美味しい新宿」とは(普通は)言いません。
こういう前提の知識があるから、人間は正しい構文を判断する事が出来ています。
「美味しい」という形容詞の意味と「新宿」という名詞の意味から判断し、構文を選択する事を意味解析と言います。
名詞や動詞など、それぞれの形態素には、色々な意味が含まれます。
「新宿」の場合には、「場所の固有名詞」「東京に含まれる」「23区の区の名前と駅の名前がある」などです。
意味解析は、単語それぞれに意味がある為、辞書登録などを通じ、その関連性を判断しています。
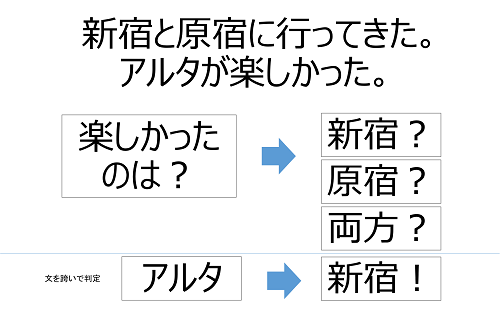
文脈認識
文脈認識とは複数の文にまたがる構文+意味解析を行なう事です。
文脈は長い文字列に即している為、単独文の意味解析よりさらに複雑な処理となります。
例えば、平仮名で「のり」と入力された場合、「海苔」「糊」等、様々な名詞が該当しますが、
人間は前後の文章から最適な名詞に脳内置換しています。
代名詞の指す対象等(「それ」)を推定したり、構文上正しいがどちらに修飾語が係っているかを判別したり、
省略された名詞等を推定する照応解析も、文脈認識に含まれます。
右図を参照すると、行ってきたのは、新宿と原宿だが、楽しかったのは意味解析を用いる事で「新宿」だったのだと解釈されます。
自然言語処理の解析工程をAIに置き換え
ディープニューラルネットワークを活用
当社では、AIアプリ開発を中心に事業を進めており、
AIデータ基盤にIoTプラットフォームをアドオンする事で、
様々な場面において、AIのマルチデバイス対応を実現してきました。
当社では自然言語処理の汎用的な機械学習モデルで高精度な結果を出した「BERT」や「GPT-3」を活用し、文章解析を行っています。
よく利用される機能をMulti AI Platformでコンポーネント化。
プロトタイプを高速で開発できるようになっています。

企業向けGPTモデルを提供する
Azure OpenAI Serivce
当社では、以前よりMicrosoft Azureを活用した自然言語認識やクラウドコンピューティングと当社の技術力を活かしたAIシステムを企業向けに提供してまいりました。「Azure OpenAI Service」の導入によって、自然言語理解とテキスト生成の両面で今までよりも最適化されたAIシステムを提供することができます。
ChatGPTでも利用されているGPT-3文章生成モデルを「SyncLect」に連携し、企業向けの独自Webシステムやスマホアプリ、チャットボットなどに対して早期に組み込む事が可能となり、Chat AnalyzerやMicrosoft Teamsアプリ、Power Platform構築においてもAzure OpenAI Serviceと連携が可能です。

SyncLect NLPによる文章解析
音声認識の欠損データ補完
音声認識技術の発展により、様々な場面で音声認識が使われるようになりました。
コールセンターの品質向上のための録音データ、スマートスピーカーに代表される音声アシスタント、入力補佐の為の音声入力。
それらの場面において、「音声認識の精度が悪い」と言われる事が多々あります。
音声情報をテキスト化する工程の事を指して「精度」と捉えられがちですが、それを補完するのが「文章解析」です。
音声情報をそのままテキスト化する技術+文章として成立しているか+前後の文章を鑑みて正しいかどうかを判断する事で、
音声情報のテキストデータを正しく抽出する事ができます。

OCRの欠損データ補完
画像情報から文字認識を行うOCRの事例も最近増えてきました。
レシートを撮影するだけで中の文字列を抜き出す、
手書きの紙に書いてある情報やPDFの中にある文字列データをデジタル変換する、
または見積書や請求書をRPAで自動化処理をする、と言ったように文字認識を行う様々な場面において、
正しく文字列を認識できない事象も多々起こっています。
この「本来抽出したかったデータ」を「文章解析」のアプローチで補完する事が可能です。

拡張アナリティクス
経営データや在庫データ、Webのデータなど、企業活動において様々なデータを駆使する場面が増えてきました。
ただ、そのデータを扱うのはアナリティクスツールやBIツールを扱う一部の人間であり、その人がわざわざレポートを作成したりして、
データを活用しているのが現状です。
自然言語処理を利用する事で、「今月の売り上げはいくらだった?」など質問する事で、その文章を解析し、BIツールを動かす事ができます。
これにより、必要だったデータにすぐに誰でもアクセスする事を可能とします。

BOTコマース
e-コマースもどんどん普及しているものの、その成長率は鈍化傾向にあります。
次に注目されているのは「音声による購入」であったり、「専門家のヒアリングによるアドバイスからの購入」と言った
デジタル上での買い物シーンとなります。
自然言語処理を用いる事で、ボットと会話しながら、買い物を楽しむ事が可能となります。
HR-Techパーソナライズ
労働力不足が国内の喫緊の課題であり、働き方改革市場は活況を極めています。
当社では、価値観モデルを応用した機械学習パーソナライズを実現しており、
人事ビッグデータから最適な求人や最適な配置策をAIがレコメンドします。
自然言語処理を施す事で、人事ビッグデータの欠損データをヒアリングにより追加していき、
機械学習の応用を推進しやすくしています。

自然言語処理型RPA
働き方改革をけん引するRPA市場ですが、「決まった作業しか対応できない」などの弱点も存在しています。
そこでAI+RPAが注目されており、OCR+RPAソリューションも多く世に出回るようになりました。
次のAIとして注目されているのが、自然言語処理型のAIです。
文章解析を組み合わせる事により、「文章内容を読み取った上で自動判断するRPA」を実現させています。

音声対話接客タブレット
労働力不足の昨今、小売流通業において、デジタルを活用した接客体験が注目されています。
タブレット端末にデジタルキャラクターを配置し、音声対話アプリケーションを動かす事で、
仮想空間のスタッフが接客や案内、よくある質問や商品紹介を行う事ができます。

業績予測AI
マーケティングリサーチや企業調査において、ホームページやSNSなどあらゆる場面から企業情報を入手する必要があります。
その一連の流れを文章解析+Webスクレイピングで実行し、必要となる情報を瞬時に集め、データベースを生成する事ができます。
